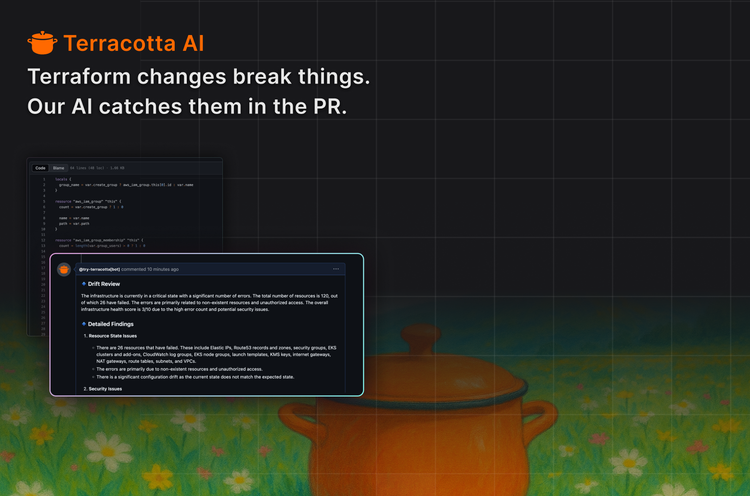
The Top 5 Bottlenecks in Self-Service Terraform (and Why They Keep Coming Back)

TL;DR
A single failed Terraform pull request can waste 15+ engineering hours and cost over $2,000 in combined platform, developer, and management time. Most of that cost comes from unclear intent, manual reviews, and late-stage fixes. The longer issues survive in the workflow, the more expensive they become.
Terraform self-service is one of those ideas that sounds obvious in theory.
Give developers reusable modules. Add guardrails. Automate plans and apply. Let teams move faster without filing tickets or waiting on a central platform group.
In practice, most organizations find that self-service Terraform shifts the bottleneck rather than removing it.
Platform teams still end up on the hook for outages, cost overruns, misconfigurations, and “how did this get merged?” incidents. The difference is that now those issues are spread across more repos, more teams, and more workflows.
After talking with dozens of enterprise platform teams, clear patterns emerge.
Here are the five most common bottlenecks organizations face when adopting self-service Terraform, along with why these issues persist and are hard to resolve permanently. Understanding and addressing these is key to scalable self-service.
State Management Becomes Everyone’s Problem
Terraform state is deceptively simple until more than one team touches it.
Once self-service is introduced, questions pile up quickly:
- Should we use a single state file or multiple ones?
- Do we split by environment, workspace, account, or service?
- How do we prevent two teams from modifying shared infrastructure at the same time?
- What happens when a state file gets corrupted or out of sync?
Without a clear, enforced strategy, teams tend to fall into one of two failure modes. Either they centralize everything into massive, fragile state files that nobody wants to touch, or they fragment state so aggressively that shared resources become impossible to reason about.
Both approaches increase risk. One makes changes terrifying. The other makes drift and duplication inevitable. Platform teams usually end up acting as human state coordinators, reviewing changes not because they want to, but because they’re the only ones who understand the blast radius.
Module Standardization Sounds Easy Until It Isn’t
Every platform team starts with good intentions: build a set of reusable, opinionated Terraform modules that encode best practices for networking, compute, IAM, databases, and more.
Then reality hits.
Modules need versioning. They need documentation. They need clear guidance on what should be overridden and what should never change. And most importantly, they need enforcement.
Developers treat modules like Lego blocks. Platform teams treat them like safety systems. That mismatch creates constant friction. One team overrides a variable to save cost. Another forks the module for a one-off use case. A third pins an old version “just for now” and never upgrades.
Over time, module sprawl takes over. The platform team becomes the only group that understands which modules are safe, deprecated, or quietly breaking standards. Reviews turn into archaeological exercises instead of approvals.
Secrets and Credentials Break the Illusion of Self-Service
Terraform self-service works great right up until credentials are involved.
Developers need access to provision infrastructure, but handing out long-lived cloud credentials is a non-starter. The “right” solution usually involves some combination of:
- OIDC federation
- Short-lived credentials
- Vault or cloud-native secret managers
- Fine-grained IAM scoping per environment or repo
Each of these is reasonable on its own. Together, they introduce many moving parts.
When this layer isn’t designed carefully, it can lead to self-service stalls. Developers can write Terraform code, but can’t apply it without platform support. Platform teams end up debugging auth issues, token expiration, or permission errors instead of focusing on architecture and reliability.
The result is a system that looks automated but still depends on humans to keep it running.
Policy Enforcement and Blast Radius Control Don’t Scale Manually
Every organization wants developers to move fast, but not that fast.
Self-service means more people can provision infrastructure, which increases the risk of non-compliant resources, surprise costs, and unintended changes with a wide blast radius. To compensate, teams introduce policy-as-code tools like Sentinel, OPA/Rego, Checkov, or custom scripts.
These tools help, but come at a cost. Writing and maintaining good policies is hard. Explaining failures to developers is often the most challenging part.
When policies are enforced late after a plan or during apply, they feel punitive. When they’re enforced early without context, they feel arbitrary. Platform teams spend hours explaining why a policy exists, rather than letting the policy explain itself.
The enforcement problem isn’t just technical. It’s communicative. And most setups don’t handle that well.
CI/CD Pipelines Become the Hidden Bottleneck
Terraform pipelines look simple until something goes wrong.
A “proper” pipeline needs to handle:
- Plan vs
applyseparation - Approval workflows
- Drift detection
- Cost estimation
- Failure recovery
- Manual intervention paths
As teams scale, pipelines grow complex. Edge cases pile up. A failed plan can block multiple teams, and a stuck apply requires someone with context to step in.
Platform teams end up maintaining pipeline logic as a product, often without the time or tooling to make it understandable to others. Developers see a red checkmark. Platform engineers know a chain of dependencies that only they can untangle.
At that point, self-service exists in name only.
Honorable Mentions (That Still Hurt)
Even teams that solve the above still struggle with:
- Uneven Terraform expertise across teams
- Outdated or ignored documentation
- Poor cost visibility until after deployment
- Multi-cloud or multi-account sprawl
These challenges are persistent and represent the ongoing difficulties faced when scaling Terraform. Recognizing and addressing these issues is central to sustainable self-service success.
The Pattern Behind All Five Bottlenecks
These problems aren’t independent. They share a common root cause.
Self-service increases surface area faster than shared understanding.
Terraform encodes what can be configured, but not why it should be configured a certain way. That intent lives in platform engineers’ heads, in old docs, or in tribal knowledge passed around during reviews.
As more teams adopt Terraform, platform teams become interpreters of intent instead of designers of systems. That’s not sustainable.
Solving self-service Terraform isn’t about adding more tools or more gates. It’s about making intent, context, and impact visible where changes actually happen.
Closing the gap between intent, context, and action is the central challenge. Recognizing this helps teams prioritize where to focus for lasting improvement in self-service Terraform.
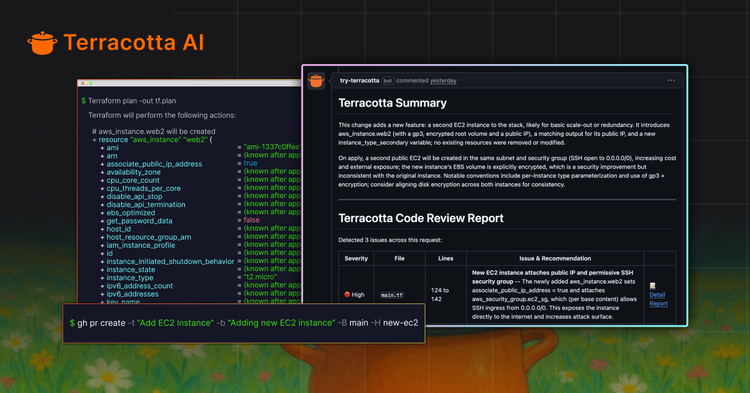
How Terracotta AI Changes the Outcome
Terracotta AI shifts Terraform governance from reactive cleanup to proactive understanding.
Instead of discovering problems after a failed apply, a broken environment, or a long review thread, Terracotta surfaces risk, intent, and impact at the moment a change is proposed. Every Terraform pull request is automatically analyzed in the context of your existing modules, environments, and infrastructure state.
Platform teams get enforceable guardrails without writing brittle policies or maintaining custom CI logic. Developers get clear, human-readable feedback that explains what went wrong, why it matters, and how to fix it without waiting on Slack or blocking reviews.
The result is fewer failed PRs, faster reviews, and infrastructure changes that behave the way the platform team intended. Governance becomes something that enables teams to move faster, not something that slows them down.
Best Practices for Scaling Terraform Without Burning Platform Teams
As Terraform adoption grows, the problem isn’t tooling it’s coordination, context, and consistency. Teams that scale successfully tend to follow a few common patterns.
First, treat Terraform changes as decisions, not just diffs. Plans should clearly explain intent, impact, and risk so reviewers don’t need deep context to understand what’s happening.
Second, encode standards where developers already work. Documentation alone doesn’t scale. Best practices need to appear automatically in pull requests, with clear explanations when they deviate.
Third, separate guidance from enforcement. Not every issue should block progress, but every issue should be visible. Advisory feedback builds trust and learning; mandatory enforcement protects production.
Finally, optimize for fewer failed PRs, not faster retries. The real cost of Terraform mistakes isn’t the apply it’s the hours lost across platform, development, and management when things go wrong.
When teams make intent explicit and feedback immediate, Terraform becomes a system that scales with the organization instead of against it.
Ready to bring clarity and governance to your established Terraform workflows? Terracotta AI helps platform teams explain, enforce, and scale infrastructure standards directly inside pull requests. Book a demo to see it in action.


Comments ()